
[Java] LeetCode(Easy) - 819. Most Common Word
문제 풀이
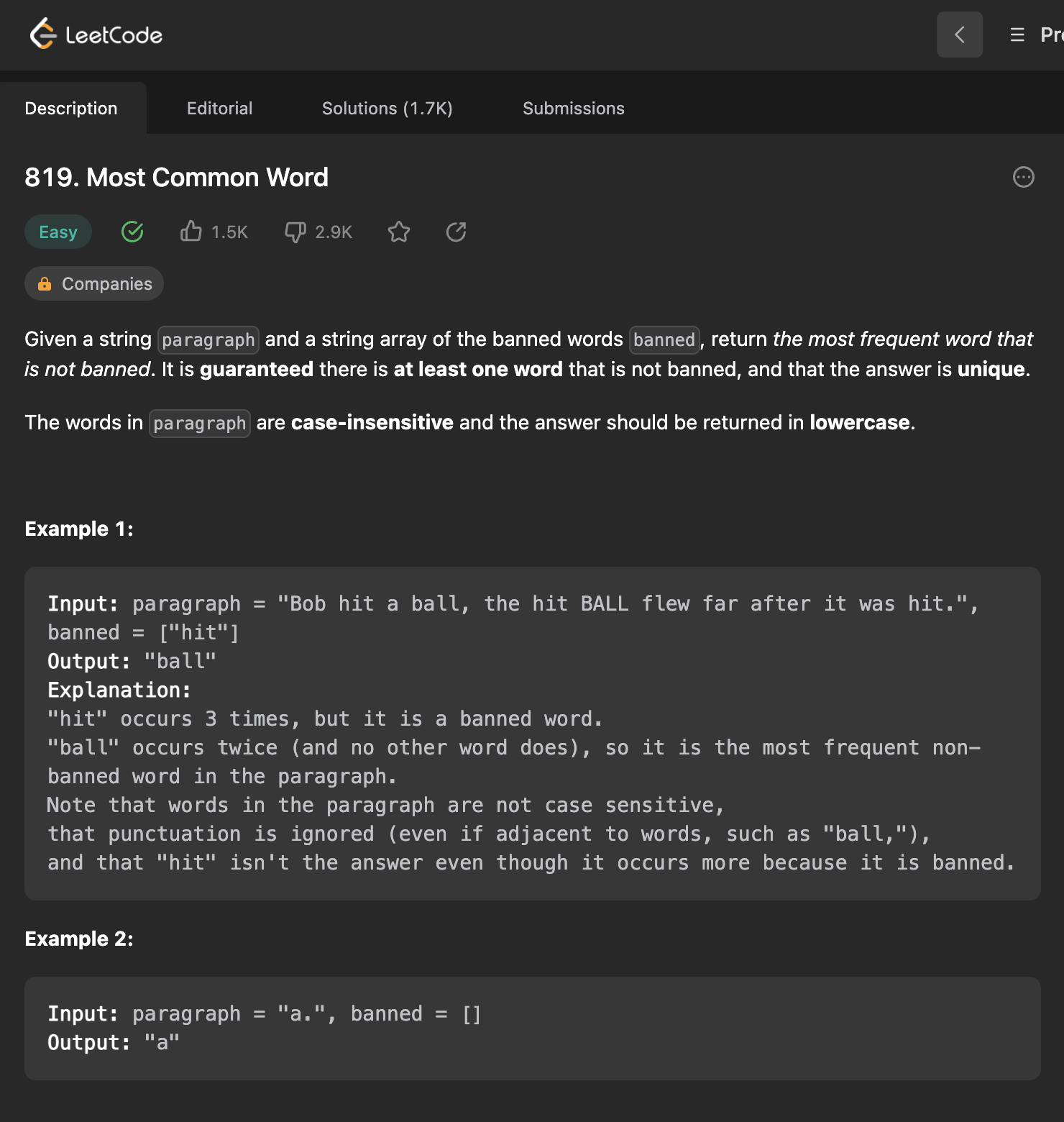
이번 819번 문제는 Most Common Word, 즉 가장 흔한 단어를 찾는 문제이다.
문제 풀이의 핵심은 정규식 및 Map을 활용하는 것이다.
아이디어 도출
문제 그대로 주어진 문자열을 토대로 빈도수가 많은 단어를 반환하면 되는데, 먼저 문제에서 요구하는 특정 문자열을 필터링하여 단어 배열을 만드는 것이 중요하다.
- 단어별로 빈도수를 담기 위해 Map을 사용한다.
- 주어진 단어의 빈도수를 세기 위해서 문자열을 소문자로 변환한다.
- 문자열에서 주어진 단락을 기준으로 단어 배열을 만든다.
!,?,',,,;,.라는 문자들과 공백 문자인 ` ` 까지 포함시켜 잘라야 한다.
- 단어 배열을 만들었다면, 해당 단어 배열을 순회하면서 단어들의 빈도수를 세어 Map에 담는다.
- 이 때, banned 배열에 포함된 단어라면 카운트를 세지 않도록 한다.
- 단어들의 빈도수를 담은 Map에서 가장 많은 빈도수를 가진 단어를 찾으면 된다.
이제 아이디어를 토대로 코드를 작성해보자.
1
2
3
String[] words = paragraph.toLowerCase().split("[!?,;'\\.\\s]+");
Map<String, Integer> count = new HashMap<>();
String answer = null;
먼저 주어진 paragraph 문자열을 소문자로 변환하고 공백 문자 및 문제에서 요구하는 문자를 기준으로 단어를 구분하기 위해 정규식을 활용하였다.
단락 필터링을 위한 정규식
문제에서 요구하는 !, ?, ', ,, ;, .라는 문자들과 공백 문자인 ` ` 문자를 기준으로 자르기 위해서는 어떻게 해야할까?
바로 정규식을 이용하여 손쉽게 해당 문자를 기준으로 문자열을 구분할 수 있도록 할 수 있다.
사용한 정규식을 살펴보면 String[] words = paragraph.toLowerCase().split("[!?,;'\\.\\s]+"); 과 같다.
이 떄 .과 ` ` 공백문자에 정규식 안에 \를 사용하여 .와 \s를 이스케이프(escape) 처리해 주었다.
이 정규식은 !, ?, ', ,, ;, . 문자와 공백문자 ` `를 구분자로 사용한다는 것을 의미한다.
여기서 []는 문자 클래스를 나타내며, 안에 들어가는 문자들 중 하나라도 매치되면 분리 기준으로 사용하겠다는 뜻이다. 또한 +는 해당 문자들이 하나 이상 연속으로 나타날 때 매치되는 것을 의미한다.
아무튼, 위와 같이 정규식을 활용하여 특정 단락에 속하는 문자를 기준으로 구분하여 split 메소드를 이용해 문자로 잘라서 배열로 만들 수 있었다.
다음으로 문자를 key로 문자들의 빈도수를 value로 담을 count HashMap을 하나 생성하고 가장 많은 빈도수를 보인 단어를 반환할 String 변수 answer를 null로 초기화한다.
1
2
3
4
5
6
7
8
9
10
for(String word : words) {
Boolean possiable = true;
for(String ban : banned) {
if(word.equals(ban)) {
possiable = false;
break;
}
}
if(possiable) count.put(word, count.getOrDefault(word, 0)+1);
}
이제 구분해낸 소문자 단어들을 순회하며 빈도수를 세도록 하자.
이 때, 해당 단어가 금지어라면 카운트를 할 필요가 없다. 그렇기에 Boolean 변수를 하나 두어서 이중 for문으로 해당 단어가 금지어인지를 확인하면 된다.
만약 금지어라면 카운트를 셀 필요가 없기 때문에 break;로 이중 for문을 탈출하면 된다. 그리고 Boolean 변수가 false이기 때문에 count HashMap에 넣지 않는다.
만약 금지어가 아니라면 카운트를 세야 하기 때문에 count HashMap에 해당 단어 문자를 key 값으로, 빈도수를 getOrDefault로 찾아와서 value 값으로 삽입한다.
그러면 구분해낸 단어들의 빈도수가 count HashMap에 온전히 담길 것이다.
1
2
3
for(String key : count.keySet()) {
if(answer == null || count.get(key) > count.get(answer)) answer = key;
}
마지막으로 count를 가지고 가장 많은 빈도수를 보인 단어를 찾으면 된다.
가장 많은 value를 가진 key값을 구하면 되기 때문에 count를 순회하면서 answer에 최대 value를 가지는 값을 담으면 된다.
작성 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class Solution {
public String mostCommonWord(String paragraph, String[] banned) {
String[] words = paragraph.toLowerCase().split("[!?,;'\\.\\s]+");
Map<String, Integer> count = new HashMap<>();
String answer = null;
for(String w : words) {
String word = w.replace("\\W", "");
Boolean possiable = true;
for(String ban : banned) {
if(word.equals(ban)) {
possiable = false;
break;
}
}
if(possiable) count.put(word, count.getOrDefault(word, 0)+1);
}
for(String key : count.keySet()) {
if(answer == null || count.get(key) > count.get(answer)) answer = key;
}
System.out.println(answer);
return answer;
}
}
회고
- 정규식을 이용하여 문자열을 원하는 패턴으로 구분할 수 있었다. 앞으로 문자열 치환이 필요할 경우 항상 정규식을 이용할 수 있는지 확인해보자.
출처
- 해당 문제의 저작권은 문제를 만든이에게 있으며 자세한 내용은 문제 링크에서 참조바랍니다.